CAREER: Ubiquitous Distributed Knowledge Discovery from Heterogeneous Data
Project Award Number
National Science Foundation CAREER Grant IIS-0093353
Principal Investigator
Hillol Kargupta
Department of Computer Science and Electrical Engineering
University of Maryland, Baltimore County
1000 Hilltop Circle, Baltimore, MD 21250
Voice : 410-455-3092, Fax : 410-455-3969
Email: hillol@cs.umbc.edu
PI URL: http://www.cs.umbc.edu/~hillol
Principal Investigator
Keywords
Ubiquitous data mining, Distributed data mining
Project Summary
Data mining deals with the problem of extracting interesting associations, classifiers, clusters, and other patterns from data by paying careful attention to computing, communication, and human-computer interaction issues. The emergence of network-based computing environments has introduced a new important dimension to this problem--distributed sources of data and computing. The Internet, corporate intranets, peer-to-peer networks, sensor-networks, and scientific data grids (e.g. network of virtual observatories) support this observation. The advent of laptops, palmtops, handhelds, wearable computers, and embedded devices is also making ubiquitous access to large quantity of distributed data a reality. Advanced analysis of distributed data for extracting useful knowledge is the next natural step in the increasingly connected world of ubiquitous computing.
Conventional off-the-shelf commercial data mining systems are designed to work as a centralized vertical application on top of a data warehouse-like architecture. The multi-organizational environments involved in typical applications considered here are by no means centralized. Since the data is likely to be voluminous, central collection of the data, followed by a centralized data mining process, may not scale up in large ubiquitous applications. Moreover, data centralization often demands heavy data communication, causes high response time, and opens up the possibility of security breach. Many applications deal with proprietary, privacy sensitive data, which does not permit moving raw data from different parties to a single central location for mining. Therefore, we need data mining algorithms and systems that work in an inherently distributed fashion----capable of performing local analysis at different sites and then combining the local models for generating a global perspective, if necessary.
The field of distributed data mining (DDM) [Kargupta & Chan 2000, Park & Kargupta, 2002] deals with this problem of analyzing data from such distributed sources without necessarily downloading all the data to a single site. DDM algorithms work by paying careful attention to the distributed data storage, communication bandwidth, computing resources, and human factors.
This project is exploring a new generation of DDM algorithms and systems for analyzing distributed and heterogeneous data in a ubiquitous environment. It has been exploring a collective approach to principal component analysis (PCA), distributed clustering using collective PCA, collective construction of decision trees through Fourier analysis, peer-to-peer data mining algorithms, and their extensions for dealing with distributed data streams . The project is also incorporating the developed techniques into an experimental ubiquitous data mining system and applying them to different practical distributed problem domains. The career plan for education is comprised of a hierarchy of strategies that reaches out to high school students, teachers and under-represented groups, promotes undergraduate and graduate education.
Publications and Products
- S. Datta, K. Bhaduri, C. Giannella, R. Wolff, H. Kargupta. (2006). Distributed Data Mining in Peer-to-Peer Networks. (Invited submission to the IEEE Internet Computing special issue on Distributed Data Mining), Volume 10, Number 4, pages 18--26.
- J. Branch, B. Szymanski, R. Wolff, C. Gianella, H. Kargupta. (2006). In-Network Outlier Detection in Wireless Sensor Networks. Proceedings of the 26th International Conference on Distributed Computing Systems (ICDCS).
- R. Wolff, K. Bhaduri, H. Kargupta. (2006). Local L2 Thresholding Based Data Mining in Peer-to-Peer Systems. Proceedings of the SIAM International Conference in Data Mining (SDM 06), Bethesda, Maryland, USA, 2006, pp. 430-441.
- S. Datta, C. Giannella, H. Kargupta. (2006). K-Means Clustering over a Large, Dynamic Network. Proc. of the SIAM International Conference in Data Mining (SDM 06), Bethesda, Maryland, USA, pp. 153-164.
- C. Giannella, H. Dutta, K. Borne, R. Wolff, H. Kargupta. (2006). Distributed Data Mining for Astronomy Catalogs. Proceedings of 9th Workshop on Mining Scientific and Engineering Datasets, as part of the SIAM International Conference on Data Mining (SDM).
- S. Mukherjee, H. Kargupta. (2006). Distributed Probabilistic Inferencing in Sensor Networks using Variational Approximation. In communication.
- S. Bandyopadhyay, C. Gianella, U. Maulik, H. Kargupta, K. Liu, and S. Datta. (2006). Clustering Distributed Data Streams in Peer-to-Peer Environments. Information Sciences , 176(14), 1952-1985.
- C. Giannella, H. Dutta, S. Mukherjee, H. Kargupta. (2006). Efficient Kernel Density Estimation Over Distributed Data.Proceedings of the 9th International Workshop on High Performance and Distributed Mining, SIAM International Data Mining Conference, Bethesda, USA. April, 2006
- K. Das, K. Bhaduri, K Liu, H. Kargupta. (2006). Distributed Identification of Top-l Inner Product Elements and its Application in a Peer-to-Peer Network. Submitted to IEEE Transaction of Knowledge and Data Engineering.
- K. Liu, K Bhaduri, K. Das, P. Nguyen, H. Kargupta (2006). Client-side Web Mining for Community Formation in Peer-to-Peer Environments. SIGKDD workshop on web usage and analysis (WebKDD). Philadelphia, Pennsylvania, USA.
- R. Wolff, K. Bhaduri, H. Kargupta. (2006). Monitoring Complex Data Models in a Large Distributed System. In communication. 2006.
- H. Kargupta, B. Park, H. Dutta. (2006). Orthogonal Decision Trees. IEEE Transactions on Knowledge and Data Engineering, volume 18, number 7, pages 1028-1042.
- H. Dutta, H. Kargupta, and A. Joshi. (2005). Orthogonal Decision Trees for Resource-Constrained Physiological Data Stream Monitoring using Mobile Devices. Accepted for publication in the 2005 High Performance Computing Conference, India.
- J. da Silva, C. Giannella, R. Bhargava, H. Kargupta, and M. Klusch. (2005) Distributed Data Mining and Agents, Invited submission, Engineering Applications of Artificial Intelligence Journal. volume 18, pages 791--807.
- H. Kargupta and M. Klein. (2005). Mining Vehicle Data Streams and Privacy-Preserving Driving Characterization. Proceedings of the 84th Annual Transportation Research Board (TRB) meeting.
- H. Kargupta and H. Dutta (2004). Orthogonal Decision Trees. The Fourth IEEE International Conference on Data Mining. Brighton, UK, pages 487--490.
- R. Chen, K. Sivakumar, and H. Kargupta. (2004). Collective Mining of Bayesian Networks from Heterogeneous Data. Knowledge and Information Systems Journal, volume 6, number 2, pages 164-187.
- D. Meng, K. Sivakumar, and H. Kargupta. (2004). Privacy Sensitive Bayesian Network Parameter Learning. Proceedings of the Fourth IEEE International Conference on Data Mining. Brighton, UK, pages 427--430.
- H. Kargupta and B. Park. (2004). A Fourier Spectrum-Based Approach to Represent Decision Trees for Mining Data Streams in Mobile Environments. IEEE Transaction on Knowledge and Data Engineering, Volume 16, Number 2, pages 216--229.
- H. Kargupta and B. Park. (2004). A Fourier Spectrum-Based Approach to Represent Decision Trees for Mining Data Streams in Mobile Environments. IEEE Transaction on Knowledge and Data Engineering, Volume 16, Number 2, pages 216--229.
- C. Giannella, K. Liu, T. Olsen, and H. Kargupta. (2004). Communication Efficient Construction of Decision Trees Over Heterogeneously Distributed Data. The Fourth IEEE International Conference on Data Mining. Brighton, UK, pages 67--74.
- H. Kargupta and K. Sivakumar, (2004) Existential Pleasures of Distributed Data Mining. Data Mining: Next Generation Challenges and Future Directions. Editors: H. Kargupta, A. Joshi, K. Sivakumar, and Y. Yesha. AAAI/MIT Press.
- H. Kargupta, R. Bhargava, K. Liu, M. Powers, P. Blair, S. Bushra, J. Dull, K. Sarkar, M. Klein, M. Vasa, and D. Handy. (2004). VEDAS: A Mobile and Distributed Data Stream Mining System for Real-Time Vehicle Monitoring. Proceedings of the SIAM International Data Mining Conference, Orlando.
- R. Bhargava, H. Kargupta and M. Powers. (2003). Energy Consumption in Data Analysis for On-board and Distributed Applications. Proceedings of the ICML'03 workshop on Machine Learning Technologies for Autonomous Space Applications.
- H. Kargupta. (2003). Fourier Representation for Meta-Level Analysis of Data Mining Models. Submitted to the Discrete Applied Mathematics Journal.
- H. Kargupta and B. Park. (2003). Mining Time-Critical Data Streams from Mobile Devices using Decision Trees and Their Fourier Spectrum. Accepted for publication in the IEEE Transaction on Knowledge and Data Engineering. (In Press).
- H. Kargupta and B. Park, S. Pittie, L. Liu, D. Kushraj and K. Sarkar. (2002). MobiMine: Monitoring the Stock Market from a PDA. ACM SIGKDD Explorations. January 2002. Volume 3, Issue 2. ACM Press.
- H. Kargupta, K. Sivakumar and S. Ghosh. (2002). Dependency Detection in MobiMine and Random Matrices. Proceedings of the 6th European Conference on Principles and Practice of Knowledge Discovery in Databases. Helsinki, Finland, pages 250-262. Verlag.
- H. Kargupta, K. Sivakumar and S. Ghosh. (2002). A Random Matrix-based Approach for Dependency Detection. Proceedings of the 2002 Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD'2002), ACM SIGMOD, Madison, USA, pages 24-29.
- B. Park and H. Kargupta. (2002). Distributed Data Mining: Algorithms, Systems, and Applications. Data Mining Handbook. Editor: Nong Ye.
- B. Park and H. Kargupta. (2002). Constructing Simpler Decision Trees from Ensemble Models Using Fourier Analysis. Proceedings of the 7th Workshop on Research Issues in Data Mining and Knowledge Discovery, ACM SIGMOD 2002. Pages 18--23.
- R. Ayyagari and H. Kargupta. (2002). A Resampling Technique for Learning the Fourier Spectrum of Skewed Data. Proceedings of the 7th Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD'2002), ACM SIGMOD, pages 39--44.
- H. Kargupta and B. Park. (2001). Mining Decision Trees from Data Streams in a Mobile Environment. Proceedings of the IEEE International Conference on Data Mining, 75--82. IEEE Press.
- H. Kargupta, W. Huang, K. Sivakumar and E. Johnson. (2001). Distributed Clustering Using Collective Principal Component Analysis. Knowledge and Information Systems Journal. Volume 3, Number 4, pages 422--448.
- H. Kargupta, K. Sivakumar, W. Huang, R. Ayyagari, R. Chen, B. Park and E. Johnson. (2001). Towards Ubiquitous Mining of Distributed Data. In Data Mining for Scientific and Engineering Applications. : Robert Grossman, Chandrika Kamath, Philip Kegelmeyer, Vipin Kumar and Raju Namburu. 281--306, Kluwer Academic Publishers.
For downloading many of these papers please follow this link....
Project Impact
(1) Research on relatively open area like ubiquitous data mining from distributed data, (2) training two PhD-level graduate students, (3) training a high school Mathematics
Goals, Objectives and Targeted Activities
The objective of this project is to perform extensive research for developing a new generation of data analysis algorithms to analyze distributed heterogeneous data. Specifically this research is developing algorithms for collective principal component analysis (CPCA), distributed clustering using CPCA, distributed construction of decision trees, orthogonal decision trees through Fourier analysis of decision trees for redundancy-free ensemble construction, and extension of these techniques for dealing with continuous data streams. This research will also incorporate the proposed techniques into an experimental DDM system and apply it for distributed data mining applications. The project has also been enhancing participation of high school students, teachers and under-represented groups in data mining related scientific research.
Area Background
This research is based on the field of distributed and ubiquitous data mining. Distributed data mining (DDM) deals with the problem of mining data from distributed sources by paying attention to the storage, computing, communication, and human factors. Ubiquitous data mining (UDM) extends the field of DDM for lightweight, ubiquitous devices.
Area References
- B. Park and H. Kargupta. (2002). Distributed Data Mining: Algorithms, Systems, and Applications. Data Mining Handbook. Editor: Nong Ye.
- H. Kargupta and K. Sivakumar. (2004). Existential Pleasures of Distributed Data Mining. Data Mining: Next Generation Challenges and Future Directions. H. Kargupta, A. Joshi, K. Sivakumar, and Y. Yesha. MIT/AAAI Press.
- H. Kargupta and K. Sivakumar. (2004). Existential Pleasures of Distributed Data Mining. Data Mining: Next Generation
Challenges and Future Directions. H. Kargupta, A. Joshi, K. Sivakumar, and Y. Yesha. MIT/AAAI Press.
Project Websites: http://www.cs.umbc.edu/~hillol/CAREER/
Illustrations
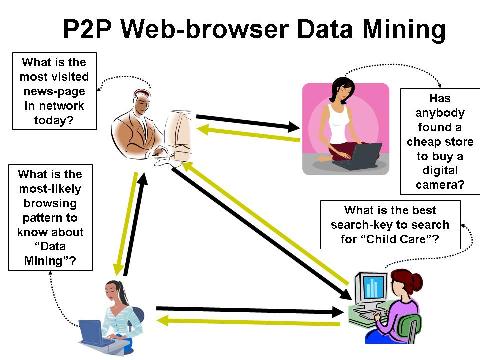
The above illustration shows how a user's browsing history can effectively be used to form online communitites of peer-to-peer members. At the heart of this framework is a distributed algorithm using an order statistics-based approach to build communities with hierarchical structure. We have also carefully considered privacy concerns of the peers and adopted cryptographic protocols to measure similarity between them without disclosing their personal profiles. Each user's browsing pattern is represented as a vector and a similarity computation between any two such vectors provides the similarity in the users' browsing patterns. This technique has been tested in a simulated environment of a large network of peers. The results are accurate and the system is scalable. Interested readers are referred to [10] for details.
Other Resources:
Distributed Data Mining Wiki (DDMWiki) (www.umbc.edu/ddm/wiki/)
Distributed Data Mining Bibliography (www.cs.umbc.edu/~hillol/DDMBIB)